Los mejores PAPERS: Inteligencia Artificial
En la ultima decada ha incrementado numero de aportes de investicacion y cada vez se integran intituciones a la siguiente revolucion: la inteligencia artificial.
Los siguientes papers son algunos de los modelos y arquitecturas de mayor impacto y con aplicaciones y tareas especificas multimodal, la cognitiva, vision por computado y el procesamiento de lenguaje natural.
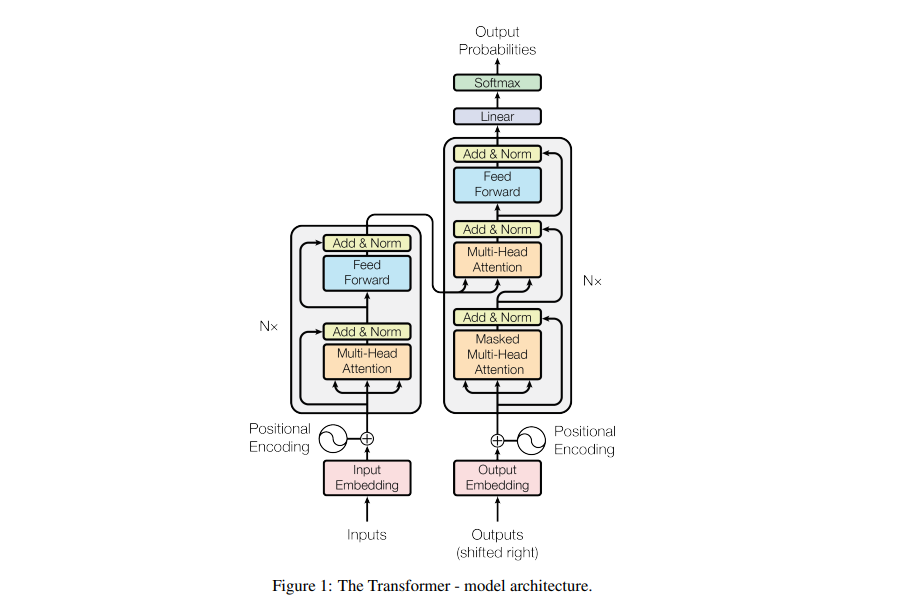
Transformers: Attention Is All You Need
Esta nueva arquitectura de red simple, el Transformador, basada únicamente en mecanismos de atención, prescindiendo por completo de la recurrencia y las convoluciones. Los experimentos en dos tareas de traducción automática muestran que estos modelos son de calidad superior, al mismo tiempo que son más paralelizables y requieren mucho menos tiempo de entrenamiento. Al igual que las redes neuronales recurrentes (RNN), los transformadores están diseñados para procesar datos de entrada secuenciales, como el lenguaje natural, con aplicaciones para tareas como la traducción y el resumen de texto . Sin embargo, a diferencia de los RNN, los transformadores procesan toda la entrada a la vez.
https://arxiv.org/pdf/1706.03762
GATO: A Generalist Agent
Gato, funciona como una política generalista multimodal, multitarea y multicorporación. La misma red con los mismos pesos puede reproducir Atari, subtitular imágenes, chatear, apilar bloques con un brazo robótico real y mucho más, decidiendo en función de su contexto si generar texto, pares de unión, pulsaciones de botones u otros tokens. En este informe, describimos el modelo y los datos, y documentamos las capacidades actuales de Gato.

U-Net
U-Net es una red y una estrategia de entrenamiento que se basa en el uso intensivo del aumento de datos para utilizar las muestras anotadas disponibles de manera más eficiente. La arquitectura consta de una ruta de contracción para capturar el contexto y una ruta de expansión simétrica que permite una localización precisa. Mostramos que una red de este tipo se puede entrenar de extremo a extremo a partir de muy pocas imágenes y supera al mejor método anterior (una red convolucional de ventana deslizante) en el desafío ISBI para la segmentación de estructuras neuronales en pilas microscópicas electrónicas. Usando la misma red entrenada en imágenes de microscopía de luz transmitida (contraste de fase y DIC), ganamos el desafío de seguimiento de células ISBI 2015 en estas categorías por un amplio margen. Es más, la red es rapida La segmentación de una imagen de 512x512 toma menos de un segundo en una GPU reciente.
Flamingo: a Visual Language Model for Few-Shot Learning
Flamingo es una familia de modelos de lenguaje visual (VLM) con capacidad de aprendizaje automatico multimodal. Proponemos innovaciones arquitectónicas clave para: (i) unir modelos poderosos de solo visión y solo de lenguaje preentrenados, (ii) manejar secuencias de datos visuales y textuales arbitrariamente intercalados, y (iii) ingerir imágenes o videos sin problemas como entradas. Gracias a su flexibilidad, los modelos de Flamingo se pueden entrenar en corpus web multimodales a gran escala que contienen texto e imágenes arbitrariamente intercalados, lo cual es clave para dotarlos de capacidades de aprendizaje en contexto de pocas tomas. Realizamos una evaluación exhaustiva de nuestros modelos, explorando y midiendo su capacidad para adaptarse rápidamente a una variedad de tareas de imagen y video.
Chinchilla: Training Compute-Optimal Large Language Models
El modelo óptimo y el tamaño del conjunto de datos para entrenar un modelo de lenguaje transformador con un presupuesto de cómputo determinado. Encontramos que los modelos de lenguaje grandes actuales están significativamente subentrenados, como consecuencia del enfoque reciente en escalar modelos de lenguaje mientras se mantiene constante la cantidad de datos de entrenamiento. Al entrenar 400 modelos de lenguaje que van desde 70 millones a 10 mil millones de parámetros en 5 a 500 mil millones de tokens, encontramos que para un entrenamiento óptimo de cómputo, el tamaño del modelo y el tamaño del conjunto de datos de entrenamiento deben escalarse por igual: por cada duplicación del tamaño del modelo, el entrenamiento el tamaño del conjunto de datos también debe duplicarse. Probamos esta hipótesis entrenando un modelo más óptimo de cómputo, Chinchilla, usando el mismo presupuesto de cómputo que Gopher pero con 70B de parámetros y 4 veces más datos. Chinchilla supera de manera uniforme y significativa a Gopher, GPT-3, Jurassic-1, y Megatron-Turing NLG en una amplia gama de tareas de evaluación posteriores. Como punto destacado, Chinchilla alcanza una precisión promedio del 67,5 % en el punto de referencia de MMLU, una mejora del 7 % con respecto a Gopher.
https://arxiv.org/pdf/2203.15556.pdf
CLIP : Learning Transferable Visual Models From Natural Language Supervision
CLIP ( Contrastive Language-Image Pre-Training ) es un método de aprendizaje de representación conjunta de imagen/texto de SOTA entrenado desde cero en un conjunto de datos de 400 millones de pares (imagen, texto) descargados de Internet. CLIP es SOTA en varios conjuntos de datos, en particular cuando se usa como un método de aprendizaje de disparo cero. Sorprendentemente, sin haber visto una sola imagen de ImageNet durante el entrenamiento, ¡supera en ImageNet a un ResNet-50 completamente entrenado
https://arxiv.org/pdf/2103.00020.pdf
DALLE-2
Hierarchical Text-Conditional Image Generation with CLIP Latents:
Se ha demostrado que los modelos contrastivos como CLIP aprenden representaciones sólidas de imágenes que capturan tanto la semántica como el estilo. Para aprovechar estas representaciones para la generación de imágenes, proponemos un modelo de dos etapas: una anterior que genera una imagen CLIP incrustada dada una leyenda de texto y un decodificador que genera una imagen condicionada a la imagen incrustada. Mostramos que la generación explícita de representaciones de imágenes mejora la diversidad de imágenes con una pérdida mínima de fotorrealismo y similitud de subtítulos. Nuestros decodificadores condicionados a representaciones de imágenes también pueden producir variaciones de una imagen que conservan tanto su semántica como su estilo, mientras varían los detalles no esenciales ausentes en la representación de la imagen. Además, el espacio de incrustación conjunta de CLIP permite manipulaciones de imágenes guiadas por el idioma en una forma de disparo cero.
Stable Diffusion: High-Resolution Image Synthesis with Latent Diffusion Models
Los modelos de difusión (DM) logran resultados de síntesis de última generación en datos de imágenes y más. Además, su formulación permite un mecanismo de guía para controlar el proceso de generación de imágenes sin volver a entrenar. Sin embargo, dado que estos modelos suelen operar directamente en el espacio de píxeles, la optimización de los DM potentes a menudo consume cientos de días de GPU y la inferencia es costosa debido a las evaluaciones secuenciales. Para habilitar el entrenamiento de DM en recursos computacionales limitados y al mismo tiempo conservar su calidad y flexibilidad, los aplicamos en el espacio latente de potentes codificadores automáticos preentrenados. A diferencia del trabajo anterior, entrenar modelos de difusión en una representación de este tipo permite por primera vez alcanzar un punto casi óptimo entre la reducción de la complejidad y la preservación de los detalles, lo que aumenta en gran medida la fidelidad visual.
ViT: Vision Transformers
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
Si bien la arquitectura Transformer se ha convertido en el estándar de facto para las tareas de procesamiento del lenguaje natural, sus aplicaciones para la visión por computadora siguen siendo limitadas. En visión, la atención se aplica junto con las redes convolucionales o se usa para reemplazar ciertos componentes de las redes convolucionales mientras se mantiene su estructura general en su lugar. Mostramos que esta dependencia de las CNN no es necesaria y que un transformador puro aplicado directamente a secuencias de parches de imagen puede funcionar muy bien en tareas de clasificación de imágenes. Cuando se entrena previamente en grandes cantidades de datos y se transfiere a múltiples puntos de referencia de reconocimiento de imágenes de tamaño mediano o pequeño (ImageNet, CIFAR-100, VTAB, etc.), Vision Transformer (ViT) logra excelentes resultados en comparación con los de última generación. redes convolucionales de última generación, mientras que requiere sustancialmente menos recursos computacionales para entrenar.

https://arxiv.org/pdf/2010.11929.pdf
Whisper
Whisper es un modelo reciente de reconocimiento automático de voz (ASR) mostrando una robustez impresionante para ambas entradas fuera de distribución y ruido aleatorio. En este trabajo mostramos que esta robustez no se traslade al ruido adversario. Generamos una entrada muy pequeña perturbaciones con Signal Noise Ratio de hasta 45dB, con lo que puede degradar drásticamente el rendimiento de Whisper, o incluso transcribir un oración objetivo de nuestra elección. También mostramos que al engañar al detector de lenguaje Whisper podemos degradar muy fácilmente el rendimiento de modelos multilingües. Estas vulnerabilidades de un modelo de código abierto ampliamente popular tienen implicaciones prácticas de seguridad y enfatizan la necesidad de ASR adversarialmente robusto.
NLLB-200: No Language Left Behind
Los modelos masivamente multilingües sufren la maldición del multilingüismo, a menos que escalen su tamaño masivamente, lo que aumenta sus costos de entrenamiento e inferencia. Los modelos Sparse Mixture-of-Experts son una forma de aumentar drásticamente la capacidad del modelo sin la necesidad de una cantidad proporcional de cómputo. El NLLB-200 lanzado recientemente es un ejemplo de este modelo. Cubre 202 idiomas, pero requiere al menos cuatro GPU de 32 GB solo para la inferencia. En este trabajo, proponemos un método de poda que permite eliminar hasta el 80\% de los expertos con una pérdida insignificante en la calidad de la traducción. lo que hace posible ejecutar el modelo en una sola GPU de 32 GB. Un análisis más detallado sugiere que nuestras métricas de poda permiten identificar expertos en idiomas específicos y podar expertos no relevantes para un par de idiomas determinado.
AlphaTensor
AlphaTensor es el primer sistema de inteligencia artificial (IA) para descubrir algoritmos novedosos, eficientes y comprobablemente correctos para tareas fundamentales como la multiplicación de matrices. Esto arroja luz sobre una pregunta matemática abierta de hace 50 años sobre cómo encontrar la forma más rápida de multiplicar dos matrices.
https://www.nature.com/articles/s41586-022-05172-4
AlphaCode:Competition-Level Code Generation with AlphaCode
Los modelos de lenguaje a gran escala recientes han demostrado una capacidad impresionante para generar código y ahora pueden completar tareas de programación simples. Sin embargo, estos modelos aún funcionan mal cuando se evalúan en problemas más complejos e invisibles que requieren habilidades de resolución de problemas más allá de la simple traducción de instrucciones a código. Por ejemplo, los problemas de programación competitivos que requieren la comprensión de algoritmos y lenguaje natural complejo siguen siendo extremadamente desafiantes. AlphaCode, un sistema para la generación de código que puede crear soluciones novedosas a estos problemas que requieren un razonamiento más profundo. En evaluaciones simuladas en competencias de programación recientes en la plataforma Codeforces, AlphaCode logró en promedio una clasificación del 54,3 % superior en competencias con más de 5000 participantes.
https://arxiv.org/pdf/2203.07814.pdf
ChatGPT: Improving on AlphaFold2 at Protein Structure Prediction
ChatGPT, un agente de inteligencia artificial (IA) desarrollado recientemente, para realizar tareas cognitivas de alto nivel y producir texto que no se puede distinguir del texto generado por humanos. Esta capacidad plantea preocupaciones sobre el uso potencial de ChatGPT como herramienta para la mala conducta académica en los exámenes en línea. El estudio encontró que ChatGPT es capaz de exhibir habilidades de pensamiento crítico y generar texto muy realista con una entrada mínima, lo que lo convierte en una amenaza potencial para la integridad de los exámenes en línea, particularmente en entornos de educación terciaria donde dichos exámenes son cada vez más frecuentes. Volver a los exámenes orales y vigilados podría formar parte de la solución, aunque el uso de técnicas de supervisión avanzadas y detectores de salida de texto de IA puede ser efectivo para abordar este problema, es probable que no sean soluciones infalibles. Se necesita más investigación para comprender completamente las implicaciones de los grandes modelos de lenguaje como ChatGPT y diseñar estrategias para combatir el riesgo de hacer trampa con estas herramientas. Es fundamental que los educadores y las instituciones sean conscientes de la posibilidad de que ChatGPT se utilice para hacer trampa y que investiguen medidas para abordarlo a fin de mantener la imparcialidad y la validez de los exámenes en línea para todos los estudiantes.

AlphaFold
Beating the Best: Improving on AlphaFold2 at Protein Structure PredictionEl objetivo del problema de predicción de la estructura de proteínas (PSP) es predecir la estructura 3D de una proteína (confirmación) a partir de su secuencia de aminoácidos. El problema ha sido el "santo grial" de la ciencia desde que el trabajo de Anfinsen, ganador del premio Nobel, demostró que la conformación de las proteínas estaba determinada por la secuencia. Un paso reciente e importante hacia este objetivo fue el desarrollo de AlphaFold2, actualmente el mejor método PSP. AlphaFold2 es probablemente la aplicación de más alto perfil de la IA para la ciencia. Tanto AlphaFold2 como RoseTTAFold (otro método impresionante de PSP) han sido publicados y colocados en el dominio público (código y modelos). El apilamiento es una forma de ML de aprendizaje automático conjunto en el que primero se aprenden múltiples modelos de referencia, luego, se aprende un metamodelo utilizando los resultados del modelo de nivel de referencia para formar un modelo que supera a los modelos base.

https://arxiv.org/ftp/arxiv/papers/2301/2301.07568.pdf
MaxViT: Multi-Axis Vision Transformer (ECCV 2022)
MaxViT es una familia de modelos híbridos de clasificación de imágenes (CNN + ViT), que logra mejores rendimientos en todos los ámbitos para la eficiencia de parámetros y FLOP que SoTA ConvNets y Transformers. También pueden escalar bien en conjuntos de datos de gran tamaño como ImageNet-21K. En particular, debido a la complejidad lineal de la atención de cuadrícula utilizada, MaxViT puede "ver" globalmente en toda la red, incluso en etapas anteriores de alta resolución.
https://arxiv.org/pdf/2204.01697.pdf
Perceiver IO: A General Architecture for Structured Inputs & Outputs
Un objetivo central del aprendizaje automático es el desarrollo de sistemas que puedan resolver muchos problemas en tantos dominios de datos como sea posible. Sin embargo, las arquitecturas actuales no se pueden aplicar más allá de un pequeño conjunto de configuraciones estereotipadas, ya que incorporan suposiciones de tareas y dominios o escalan de manera deficiente a grandes entradas o salidas. La arquitectura de Perceiver IO, es una arquitectura de propósito general que maneja datos de configuraciones arbitrarias mientras escala linealmente con el tamaño de las entradas y salidas. Nuestro modelo aumenta el Perceptor con un mecanismo de consulta flexible que permite salidas de varios tamaños y semánticas, eliminando la necesidad de ingeniería de arquitectura específica de la tarea. La misma arquitectura logra buenos resultados en tareas que abarcan lenguaje natural y comprensión visual, razonamiento multitarea y multimodal, y StarCraft II.
https://arxiv.org/pdf/2107.14795.pdf